Note: this document discuss Mach-O port of LLD. For ELF and COFF, see LLD - The LLVM Linker.
lld is a new generation of linker. It is not “section” based like traditional linkers which mostly just interlace sections from multiple object files into the output file. Instead, lld is based on “Atoms”. Traditional section based linking work well for simple linking, but their model makes advanced linking features difficult to implement. Features like dead code stripping, reordering functions for locality, and C++ coalescing require the linker to work at a finer grain.
An atom is an indivisible chunk of code or data. An atom has a set of attributes, such as: name, scope, content-type, alignment, etc. An atom also has a list of References. A Reference contains: a kind, an optional offset, an optional addend, and an optional target atom.
The Atom model allows the linker to use standard graph theory models for linking data structures. Each atom is a node, and each Reference is an edge. The feature of dead code stripping is implemented by following edges to mark all live atoms, and then delete the non-live atoms.
An atom is an indivisible chunk of code or data. Typically each user written function or global variable is an atom. In addition, the compiler may emit other atoms, such as for literal c-strings or floating point constants, or for runtime data structures like dwarf unwind info or pointers to initializers.
A simple “hello world” object file would be modeled like this:
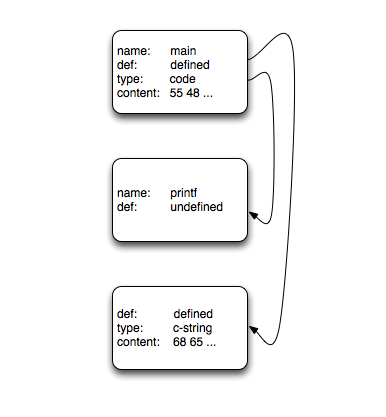
There are three atoms: main, a proxy for printf, and an anonymous atom containing the c-string literal “hello world”. The Atom “main” has two references. One is the call site for the call to printf, and the other is a reference for the instruction that loads the address of the c-string literal.
There are only four different types of atoms:
- DefinedAtom
95% of all atoms. This is a chunk of code or data
- UndefinedAtom
This is a place holder in object files for a reference to some atom outside the translation unit.During core linking it is usually replaced by (coalesced into) another Atom.
- SharedLibraryAtom
If a required symbol name turns out to be defined in a dynamic shared library (and not some object file). A SharedLibraryAtom is the placeholder Atom used to represent that fact.
It is similar to an UndefinedAtom, but it also tracks information about the associated shared library.
- AbsoluteAtom
This is for embedded support where some stuff is implemented in ROM at some fixed address. This atom has no content. It is just an address that the Writer needs to fix up any references to point to.
The linker views the input files as basically containers of Atoms and References, and just a few attributes of their own. The linker works with three kinds of files: object files, static libraries, and dynamic shared libraries. Each kind of file has reader object which presents the file in the model expected by the linker.
An object file is just a container of atoms. When linking an object file, a reader is instantiated which parses the object file and instantiates a set of atoms representing all content in the .o file. The linker adds all those atoms to a master graph.
This is the traditional unix static archive which is just a collection of object files with a “table of contents”. When linking with a static library, by default nothing is added to the master graph of atoms. Instead, if after merging all atoms from object files into a master graph, if any “undefined” atoms are left remaining in the master graph, the linker reads the table of contents for each static library to see if any have the needed definitions. If so, the set of atoms from the specified object file in the static library is added to the master graph of atoms.
Through the use of abstract Atoms, the core of linking is architecture independent and file format independent. All command line parsing is factored out into a separate “options” abstraction which enables the linker to be driven with different command line sets.
The overall steps in linking are:
- Command line processing
- Parsing input files
- Resolving
- Passes/Optimizations
- Generate output file
The Resolving and Passes steps are done purely on the master graph of atoms, so they have no notion of file formats such as mach-o or ELF.
Existing developer tools using different file formats for object files. A goal of lld is to be file format independent. This is done through a plug-in model for reading object files. The lld::Reader is the base class for all object file readers. A Reader follows the factory method pattern. A Reader instantiates an lld::File object (which is a graph of Atoms) from a given object file (on disk or in-memory).
Every Reader subclass defines its own “options” class (for instance the mach-o Reader defines the class ReaderOptionsMachO). This options class is the one-and-only way to control how the Reader operates when parsing an input file into an Atom graph. For instance, you may want the Reader to only accept certain architectures. The options class can be instantiated from command line options, or it can be subclassed and the ivars programmatically set.
The resolving step takes all the atoms’ graphs from each object file and combines them into one master object graph. Unfortunately, it is not as simple as appending the atom list from each file into one big list. There are many cases where atoms need to be coalesced. That is, two or more atoms need to be coalesced into one atom. This is necessary to support: C language “tentative definitions”, C++ weak symbols for templates and inlines defined in headers, replacing undefined atoms with actual definition atoms, and for merging copies of constants like c-strings and floating point constants.
The linker support coalescing by-name and by-content. By-name is used for tentative definitions and weak symbols. By-content is used for constant data that can be merged.
The resolving process maintains some global linking “state”, including a “symbol table” which is a map from llvm::StringRef to lld::Atom*. With these data structures, the linker iterates all atoms in all input files. For each atom, it checks if the atom is named and has a global or hidden scope. If so, the atom is added to the symbol table map. If there already is a matching atom in that table, that means the current atom needs to be coalesced with the found atom, or it is a multiple definition error.
When all initial input file atoms have been processed by the resolver, a scan is made to see if there are any undefined atoms in the graph. If there are, the linker scans all libraries (both static and dynamic) looking for definitions to replace the undefined atoms. It is an error if any undefined atoms are left remaining.
Dead code stripping (if requested) is done at the end of resolving. The linker does a simple mark-and-sweep. It starts with “root” atoms (like “main” in a main executable) and follows each references and marks each Atom that it visits as “live”. When done, all atoms not marked “live” are removed.
The result of the Resolving phase is the creation of an lld::File object. The goal is that the lld::File model is the internal representation throughout the linker. The file readers parse (mach-o, ELF, COFF) into an lld::File. The file writers (mach-o, ELF, COFF) taken an lld::File and produce their file kind, and every Pass only operates on an lld::File. This is not only a simpler, consistent model, but it enables the state of the linker to be dumped at any point in the link for testing purposes.
The Passes step is an open ended set of routines that each get a change to modify or enhance the current lld::File object. Some example Passes are:
- stub (PLT) generation
- GOT instantiation
- order_file optimization
- branch island generation
- branch shim generation
- Objective-C optimizations (Darwin specific)
- TLV instantiation (Darwin specific)
- DTrace probe processing (Darwin specific)
- compact unwind encoding (Darwin specific)
Some of these passes are specific to Darwin’s runtime environments. But many of the passes are applicable to any OS (such as generating branch island for out of range branch instructions).
The general structure of a pass is to iterate through the atoms in the current lld::File object, inspecting each atom and doing something. For instance, the stub pass, looks for call sites to shared library atoms (e.g. call to printf). It then instantiates a “stub” atom (PLT entry) and a “lazy pointer” atom for each proxy atom needed, and these new atoms are added to the current lld::File object. Next, all the noted call sites to shared library atoms have their References altered to point to the stub atom instead of the shared library atom.
Once the passes are done, the output file writer is given current lld::File object. The writer’s job is to create the executable content file wrapper and place the content of the atoms into it.
lld uses a plug-in model for writing output files. All concrete writers (e.g. ELF, mach-o, etc) are subclasses of the lld::Writer class.
Unlike the Reader class which has just one method to instantiate an lld::File, the Writer class has multiple methods. The crucial method is to generate the output file, but there are also methods which allow the Writer to contribute Atoms to the resolver and specify passes to run.
An example of contributing atoms is that if the Writer knows a main executable is being linked and such an executable requires a specially named entry point (e.g. “_main”), the Writer can add an UndefinedAtom with that special name to the resolver. This will cause the resolver to issue an error if that symbol is not defined.
Sometimes a Writer supports lazily created symbols, such as names for the start of sections. To support this, the Writer can create a File object which vends no initial atoms, but does lazily supply atoms by name as needed.
Every Writer subclass defines its own “options” class (for instance the mach-o Writer defines the class WriterOptionsMachO). This options class is the one-and-only way to control how the Writer operates when producing an output file from an Atom graph. For instance, you may want the Writer to optimize the output for certain OS versions, or strip local symbols, etc. The options class can be instantiated from command line options, or it can be subclassed and the ivars programmatically set.
Just as LLVM has three representations of its IR model, lld has two representations of its File/Atom/Reference model:
- In memory, abstract C++ classes (lld::Atom, lld::Reference, and lld::File).
- textual (in YAML)
In designing a textual format we want something easy for humans to read and easy for the linker to parse. Since an atom has lots of attributes most of which are usually just the default, we should define default values for every attribute so that those can be omitted from the text representation. Here is the atoms for a simple hello world program expressed in YAML:
target-triple: x86_64-apple-darwin11
atoms:
- name: _main
scope: global
type: code
content: [ 55, 48, 89, e5, 48, 8d, 3d, 00, 00, 00, 00, 30, c0, e8, 00, 00,
00, 00, 31, c0, 5d, c3 ]
fixups:
- offset: 07
kind: pcrel32
target: 2
- offset: 0E
kind: call32
target: _fprintf
- type: c-string
content: [ 73, 5A, 00 ]
...
The biggest use for the textual format will be writing test cases. Writing test cases in C is problematic because the compiler may vary its output over time for its own optimization reasons which my inadvertently disable or break the linker feature trying to be tested. By writing test cases in the linkers own textual format, we can exactly specify every attribute of every atom and thus target specific linker logic.
The textual/YAML format follows the ReaderWriter patterns used in lld. The lld library comes with the classes: ReaderYAML and WriterYAML.
The lld project contains a test suite which is being built up as new code is added to lld. All new lld functionality should have a tests added to the test suite. The test suite is lit driven. Each test is a text file with comments telling lit how to run the test and check the result To facilitate testing, the lld project builds a tool called lld-core. This tool reads a YAML file (default from stdin), parses it into one or more lld::File objects in memory and then feeds those lld::File objects to the resolver phase.
Basic testing is the “core linking” or resolving phase. That is where the linker merges object files. All test cases are written in YAML. One feature of YAML is that it allows multiple “documents” to be encoding in one YAML stream. That means one text file can appear to the linker as multiple .o files - the normal case for the linker.
Here is a simple example of a core linking test case. It checks that an undefined atom from one file will be replaced by a definition from another file:
# RUN: lld-core %s | FileCheck %s
#
# Test that undefined atoms are replaced with defined atoms.
#
---
atoms:
- name: foo
definition: undefined
---
atoms:
- name: foo
scope: global
type: code
...
# CHECK: name: foo
# CHECK: scope: global
# CHECK: type: code
# CHECK-NOT: name: foo
# CHECK: ...
Since Passes just operate on an lld::File object, the lld-core tool has the option to run a particular pass (after resolving). Thus, you can write a YAML test case with carefully crafted input to exercise areas of a Pass and the check the resulting lld::File object as represented in YAML.
There are a number of open issues in the design of lld. The plan is to wait and make these design decisions when we need to.
Currently, the lld model says nothing about debug info. But the most popular debug format is DWARF and there is some impedance mismatch with the lld model and DWARF. In lld there are just Atoms and only Atoms that need to be in a special section at runtime have an associated section. Also, Atoms do not have addresses. The way DWARF is spec’ed different parts of DWARF are supposed to go into specially named sections and the DWARF references function code by address.
Currently, lld has an abstract “Platform” that deals with any CPU or OS specific differences in linking. We just keep adding virtual methods to the base Platform class as we find linking areas that might need customization. At some point we’ll need to structure this better.
Currently, lld::File just has a path and a way to iterate its atoms. We will need to add more attributes on a File. For example, some equivalent to the target triple. There is also a number of cached or computed attributes that could make various Passes more efficient. For instance, on Darwin there are a number of Objective-C optimizations that can be done by a Pass. But it would improve the plain C case if the Objective-C optimization Pass did not have to scan all atoms looking for any Objective-C data structures. This could be done if the lld::File object had an attribute that said if the file had any Objective-C data in it. The Resolving phase would then be required to “merge” that attribute as object files are added.