Performance¶
High-Performance Generalized Matrix Multiplication¶
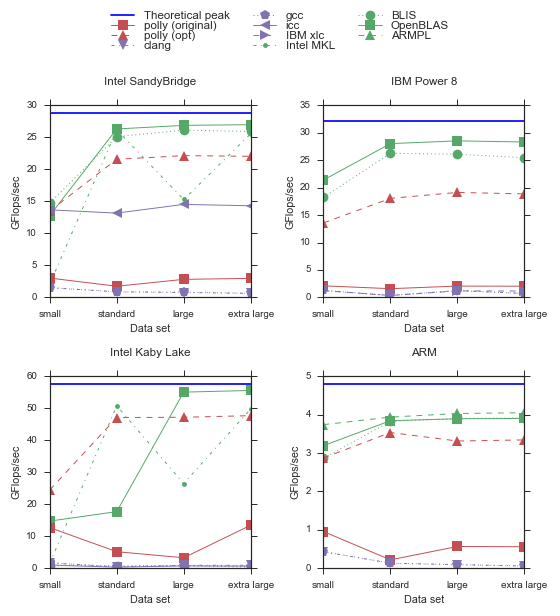
Polly automatically detects and optimizes generalized matrix multiplication, the computation C ← α ⊗ C ⊕ β ⊗ A ⊗ B, where A, B, and C are three appropriately sized matrices, ⊕ and ⊗ operations are originating from the corresponding matrix semiring, and α and β are constants, and beta is not equal to zero. It allows to obtain the highly optimized form structured similar to the expert implementation of GEMM that can be found in GotoBLAS and its successors. The performance evaluation of GEMM is shown in the following figure.
Compile Time Impact of Polly¶
Clang+LLVM+Polly are compiled using Clang on a Intel(R) Core(TM) i7-7700 based system. The experiment is repeated twice: with and without Polly enabled in order to measure its compile time impact.
The following versions are used:
- Polly (git hash 0db98a4837b6f233063307bb9184374175401922)
- Clang (git hash 3e1d04a92b51ed36163995c96c31a0e4bbb1561d)
- LLVM git hash 0265ec7ebad69a47f5c899d95295b5eb41aba68e)
ninja is used as the build system.
For both cases the whole compilation was performed five times. The compile times in seconds are shown in the following table.
| Compile Time | |
|---|---|
| Polly Disabled | Polly Enabled |
| 964 | 977 |
| 964 | 980 |
| 967 | 981 |
| 967 | 981 |
| 968 | 982 |
The median compile time without Polly enabled is 967 seconds and with Polly enabled it is 981 seconds. The overhead is 1.4%.